Detta är artikel 3 i en artikelserie om grön IT.
Har du någonsin tänkt på den enorma mängden data som genereras globalt varje minut? Sedan 2013 ger ’Data Never Sleeps Infographic’(1) inblick i detta. År 2022 skickade vi till exempel 231,4 miljoner e-postmeddelanden varje minut, delade 66 000 foton på Instagram och laddade upp 500 timmar videoklipp på YouTube. Imponerande siffror, särskilt när man tänker på att all denna data hamnar på olika platser – och sällan raderas.
Bytes och ännu mer bytes
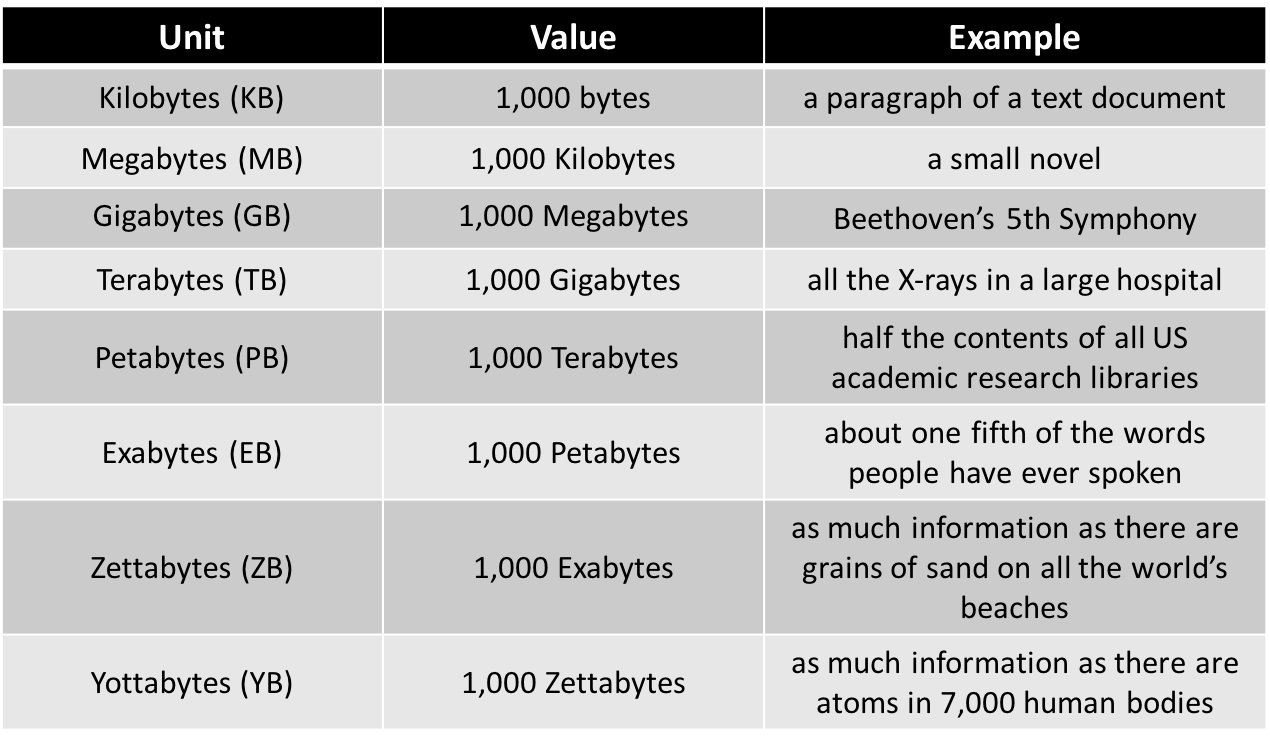
International Data Corporation förutspår att den globala databergen kommer att växa till 166 Zettabytes år 2025 och till och med till 221 Zettabytes år 2026(2). Siffror som kanske inte ger omedelbar känsla. För att ge dig en bättre bild har MyNASA Data(3) placerat dataenheter i ett tilltalande perspektiv:
|
Enhet |
Värde |
Exempel |
|
Kilobytes (kB) |
1.000 bytes |
Ett stycke text i ett dokument |
|
Megabytes (MB) |
1.000 Kilobytes |
En liten roman |
|
Gigabytes (GB) |
1.000 Megabytes |
Beethovens 5:e symfoni |
|
Terabytes (TB) |
1.000 Gigabytes |
Alla röntgenbilder på ett stort sjukhus |
|
Petabytes (PB) |
1.000 Terabytes |
Hälften av samlingen på alla akademiska forskningsbibliotek i USA |
|
Exabytes (EB) |
1.000 Petabytes |
Ungefär en femtedel av alla ord som någonsin uttalats av människor |
|
Zettabytes (ZB) |
1.000 Exabytes |
Samma mängd information som det finns sandkorn på alla stränder i världen |
|
Yottabytes (YB) |
1.000 Zettabytes |
Samma mängd information som det finns atomer i 7 000 mänskliga kroppar |
Exemplen i den tredje kolumnen i tabellen ger en uppfattning om hur omfattande databerget är. År 2026 förväntas den totala datamängden vara hela 200 gånger större än antalet sandkorn på alla världens stränder. Se också YouTube-videon från Techtarget, med titeln: ’What are Kilo, Mega, Giga, Tera, Peta, Exa, Zetta and All That?’, som förklarar på ett enkelt sätt hur datavolym mäts(4).
Är all denna data nödvändig? Lär känna dark data
När vi fokuserar på global datalagring visar det sig att 60-70 procent av datan som genereras inom en organisation kan klassificeras som dark data(5). Denna data inkluderar information som organisationer samlar in, bearbetar och lagrar under sin dagliga verksamhet, men som sedan inte används för andra ändamål(6). Ett exempel på detta är till exempel ett separat dokument med anteckningar som omvandlas till en rapport. Även om denna information inte längre aktivt används, lagras den och ingår i säkerhetskopior, vilket – när den är i molnet – leder till kontinuerlig energiförbrukning.
Denna aspekt framkom även i undersökningen ’Veritas: The UK 2020 Databerg Report Revisited’(7). I denna undersökning analyserade Veritas och Vanson Bourne det växande databerget åren 2015 och 2020 och jämförde det med den metaforiska isbergets spets. Större delen finns under ytan, utanför vår syn. Kort sagt är den verkliga omfattningen av databergen många gånger större än vad vi vanligtvis uppfattar.
Forskarna bakom Databerg-rapporten ser, som tidigare nämnts, datan ’under vattenytan’ som dark data. Detta är data där det är oklart vad den används till. Forskarna använder också kategorin ROT-data, vilket står för Redundant, Obsolete eller Trivial data. Med andra ord: data som inte längre är relevant, har liten eller inget värde för organisationen eller som är lagrad på flera platser. Ett annat exempel på detta är exempelvis protokoll som skickas runt och sparas av varje mottagare.
Större delen av lagrade data är överflödig
När man lägger samman båda kategorierna visar det sig att år 2015 kunde 88 procent och år 2020 81 procent av all data klassificeras som dark eller ROT-data. Vi ser också att år 2015 var 12 procent och år 2020 19 procent av data av affärskritisk betydelse, det vill säga data som man vill (och ofta måste) spara. Här ser vi alltså en liten förskjutning. Detta beror på att fler organisationer har antagit en strategi för att märka sin data och hitta ROT-data. Författarna till Veritas-rapporten noterar dock att denna strategi har begränsad effekt eftersom organisationer ofta saknar resurser för att verkligen hantera detta komplexa problem.

Konsekvenserna av dark data
När endast 19 procent av datan kan klassificeras som användbar affärskritisk data och 81 procent som dark och ROT-data slösar en organisation onödigt mycket pengar på lagrings- och underhållskostnader. Enligt nederländska Joost Rutgers i hans LinkedIn-inlägg ’Hoe ROT zijn de gegevens in uw organisatie??’(8) leder detta inte bara till produktivitetsförlust utan också till problem med efterlevnad och säkerhet. Detta beror på att en organisation inte vet vilken data de äger och var den finns i organisationen. Problemet med energiförbrukningen och det därmed sammanhängande (onödiga) CO2-utsläppet för att hålla all denna data tillgänglig nämns här ännu inte. Det är alltså av flera skäl viktigt att organisationer regelbundet granskar sina informationsfiler och uppmuntrar medarbetare att städa upp sin digitala arbetsmiljö.
Var med på Digital Clean Up Day
Den okontrollerade tillväxten av information fick den franska IT-specialist Kevin Guerin att organisera den första upplagan av Digital Clean Up Day 2020. Syftet med denna dag, inspirerad av World Clean Up Day(9), är att skapa medvetenhet globalt om den ekologiska påverkan av den digitala industrin. Initiativet uppmuntrar människor att agera genom att rensa upp sina digitala data. Huvudsyftet är att ge oanvänd utrustning som bara ligger och skräpar ett nytt liv.
Vad som började som ett lokalt initiativ i Frankrike spred sig snabbt till Italien och Schweiz. Under Digital Clean Up Day 2022 deltog människor från 124 olika länder och totalt raderades 530 884 GB data – en besparing av 133 ton CO2-utsläpp per år.
Kom igång – det är mycket enkelt
Hur mycket dark data finns det i din organisation? Och på din privata dator? Hur mycket utrymme och CO2-utsläpp kan du spara genom att ta bort onödiga data? Praktiska steg-för-steg-planer hittar du på Digital Clean Up Days webbplats(10).
Nästa artikel
I nästa artikel tittar vi på lagring av data i molnet, den vanligaste lagringsmetoden, och vi granskar datacentras påverkan på det föränderliga klimatet.
Tidigare publicerad i denna artikelserie
Tema: Introduktion grön IT
Källor
- ’Data Never Sleeps’ infografikerna finns på https://www.domo.com/data-never-sleeps (senast besökt 5 oktober 2023).
- IDC, ‘High Data Growth and Modern Applications Drive New Storage Requirements in Digitally Transformed Enterprises: a whitepaper sponsored by Dell Technologies and NVIDIA’, publicerad juli 2022.
- Tabell från MyNasaData: https://mynasadata.larc.nasa.gov/sites/default/files/inline-images/datavolume_0.png
- YouTube-videon från TechTarget ‘What are Kilo, Mega, Giga, Tera, Peta, Exa, Zetta and All That?’, publicerad i 2020.
- Zippia ’26 Stunning Big Data Statistics (2023): Market Size, Trends and Facts’ publicerad 16 januari 2023.
- Gartner, ‘IT Gartner Glossary: dark data’ (senast besökt 5 oktober 2023).
- Veritas: The UK 2020 Databerg Report Revisited, publicerad i 2020.
- Rutgers, Joost, ‘Hoe ROT zijn de gegevens in uw organisatie??’, Linkedin Post från 28 april 2022.
- World Clean Up Day är en dag då miljontals frivilliga världen över går ut på gatorna för att samla skräp. För mer information, besök https://www.worldcleanupday.org/
- Instruktioner och verktyg för att komma igång med digital städning finns på webbplatsen för Digital Clean Up Day: https://www.digitalcleanupday.org/home/resources-and-materials/
{kind=link}
Om artikelserien
Denna artikelserie är författad av Tineke van Heijst från nederländska Van Heijst Information Consulting (VHIC) på uppdrag av den nederländska gruppen Network Digital Heritage (NDE). NDE har till uppgift att övervaka utvecklingen av grön IT (ibland kallad hållbar IT eller Green IT) och dess påverkan på klimatet i den framstegsvänliga digitaliseringen. Särskild uppmärksamhet ägnas åt den växande digitaliseringen inom kultursektorn.
Arkeion har fått godkännande från VHIC att översätta och publicera artikelserien på sin webbplats. Översättningen utfördes av Caspar Almalander.
Syftet med denna serie är att bistå kulturarvsinstitutioner att få en djupare förståelse för grön IT (Green IT), vilket möjliggör diskussioner kring detta viktiga ämne inom deras egna organisationer.
Tidigare artiklar
Grön mjukvara: Mäta för att veta och förbättra
Del 13: När det gäller grön mjukvara är det viktigt att förstå hur din organisation bidrar. Det är inte bara att mäta för att veta, utan också att mäta för att förbättra.
Grön mjukvara: Förläng livslängden på din (begagnade) IT-utrustning
Del 12: När vi mäter påverkan från IT är det viktigt att även ta med produktionen av den hårdvara du använder, såsom datorer, mobiltelefoner och kablar.
Grön mjukvara: Gör mer när energin är renare
Del 11: Grön energi är inte alltid lika tillgänglig och beror oftast på väderförhållanden. Den tredje principen för grön mjukvara fokuserar på kreativa lösningar.
Grön mjukvara: mindre energi = mindre koldioxid-utsläpp
Del 10: Dåligt programmerad eller felanvänd mjukvara bidrar till IT-sektorns CO2-fotavtryck. Men allt fler fokuserar på att minska energiförbrukningen och CO2-utsläpp.